Neural Networks in Python


Artificial Neural Networks are a mathematical model, inspired by the brain, that is often used in machine learning. It was initially proposed in the '40s and there was some interest initially, but it waned soon due to the inefficient training algorithms used and the lack of computing power. More recently however they have started to be used again, especially since the introduction of autoencoders, convolutional nets, dropout regularization and other techniques that improve their performance significantly.
Here I will present a simple multi-layer perceptron, implemented in Python using numpy.
Neural networks are formed by neurons that are connected to each others and that send each other signals. If the number of signals a neuron received is over a threshold, it then sends a signal to neurons it is connected. In the general case, the connections can be between any neurons, even to themselves, but it gets pretty hard to train them, so in most cases there are several restrictions to them.
In the case of the multi-layer perceptron, neurons are arranged into layers, and each neuron sends signals only to the next neurons in the following layer. The first layer consists of the input data, while the last layer is called the output layer and contains the predicted values.
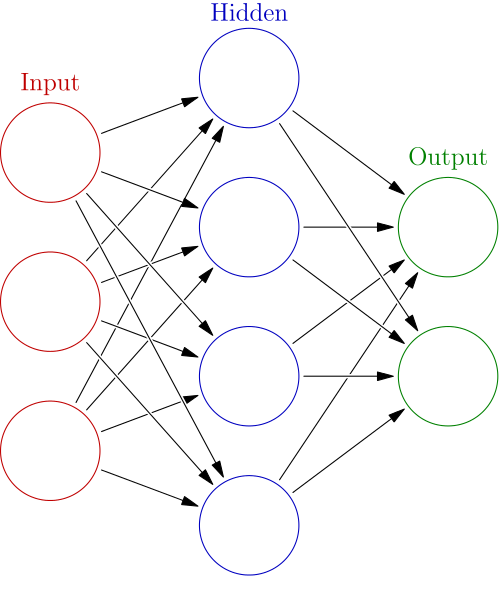
Instead of using a hard threshold to decide whether to send a signal or not (this has the disadvantage of not being a differentiable function), multilayer perceptrons use sigmoid functions such as the hyperbolic tangent or the logistic function \( f(x) = \frac{1}{1+e^{-x}} \)
The most common algorithm used to train MLPs is the backpropagation algorithm. It has two phases:
- A forward pass, in which the training data is run through the network to obtain it's output
- A backward pass, in which, starting from the output, the errors for each neuron are calculated and then used to adjust the weight of the network.
That's the rough summary of the algorithm, so let's start implementing it.
First, we define our activation functions and their derivatives, using numpy.
import numpy as np
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x)**2
def logistic(x):
return 1/(1 + np.exp(-x))
def logistic_derivative(x):
return logistic(x)*(1-logistic(x))In the constructor of the class we will need to set the number of neurons in each layer, initialize their weights randomly between -0.25 and 0.25 and set the activation function to be used. Each layer, except the last one, will also have a bias unit which corresponds to the threshold value for the activation.
class NeuralNetwork:
def __init__(self, layers, activation='tanh'):
"""
:param layers: A list containing the number of units in each layer.
Should be at least two values
:param activation: The activation function to be used. Can be
"logistic" or "tanh"
"""
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
for i in range(1, len(layers) - 1):
self.weights.append((2*np.random.random((layers[i - 1] + 1, layers[i]
))-1)*0.25)
self.weights.append((2*np.random.random((layers[i] + 1, layers[i +
1]))-1)*0.25)Now we get to the fun part: the training. Given a set of input vectors X and output values y, adjust the weights appropiately. The algorithm we will use is called stochastic gradient descent, which chooses randomly a sample from the training data and does the backpropagation for that sample, and this is repeated for a number of times (called epochs). We also have to set the learning rate of the algorithm, which determines how big a change occurs in the weights each time (proportionally to the errors).
def fit(self, X, y, learning_rate=0.2, epochs=10000):
X = np.atleast_2d(X)
temp = np.ones([X.shape[0], X.shape[1]+1])
temp[:, 0:-1] = X # adding the bias unit to the input layer
X = temp
y = np.array(y)
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]]
for l in range(len(self.weights)):
hidden_inputs = np.ones([self.weights[l].shape[1] + 1])
hidden_inputs[0:-1] = self.activation(np.dot(a[l], self.weights[l]))
a.append(hidden_inputs)
error = y[i] - a[-1][:-1]
deltas = [error * self.activation_deriv(a[-1][:-1])]
l = len(a) - 2
# The last layer before the output is handled separately because of
# the lack of bias node in output
deltas.append(deltas[-1].dot(self.weights[l].T)*self.activation_deriv(a[l]))
for l in range(len(a) -3, 0, -1): # we need to begin at the second to last layer
deltas.append(deltas[-1][:-1].dot(self.weights[l].T)*self.activation_deriv(a[l]))
deltas.reverse()
for i in range(len(self.weights)-1):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta[:,:-1])
# Handle last layer separately because it doesn't have a bias unit
i+=1
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)And now the useful part: prediction. This is pretty much the same as the forward pass part of backpropagation, except we don't need to keep all the values of the activations for each neuron, so we keep only the last one.
def predict(self, x):
a = np.array(x)
for l in range(0, len(self.weights)):
temp = np.ones(a.shape[0]+1)
temp[0:-1] = a
a = self.activation(np.dot(temp, self.weights[l]))
return aAnd that's it. 50 lines of code for the neural network itself, plus 10 more for the activation functions. So lets test it.
Let's start with something simple: the XOR function. The XOR function is not linearly separable (if we represent it in plane, there is no line that can separate the points with label 1 from the points with label 0), and this means we need at least one hidden layer. We will use it with 2 units.
nn = NeuralNetwork([2,2,1], 'tanh')
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
nn.fit(X, y)
for i in [[0, 0], [0, 1], [1, 0], [1,1]]:
print(i,nn.predict(i))And the output is:
([0, 0], array([ 4.01282568e-05]))
([0, 1], array([ 0.98765949]))
([1, 0], array([ 0.98771753]))
([1, 1], array([ 0.00490502]))Pretty good. If we instead used a step function for the activations in the output layer, we would get the exact results.
Now let's take a look at something slightly more complicated: the digits dataset that comes included with scikit-learn. This has 1797 8x8 pixel images of digits with their labels. Lets see what accuracies can we get on them. We will have to transform the labels from values (such as 1 or 5), to vectors of 10 elements, which are all 0 except for the position corresponding to the label, which will be one.
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.datasets import load_digits
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.preprocessing import LabelBinarizer
from NeuralNetwork import NeuralNetwork
digits = load_digits()
X = digits.data
y = digits.target
X -= X.min() # normalize the values to bring them into the range 0-1
X /= X.max()
nn = NeuralNetwork([64,100,10],'tanh')
X_train, X_test, y_train, y_test = train_test_split(X, y)
labels_train = LabelBinarizer().fit_transform(y_train)
labels_test = LabelBinarizer().fit_transform(y_test)
nn.fit(X_train,labels_train,epochs=30000)
predictions = []
for i in range(X_test.shape[0]):
o = nn.predict(X_test[i] )
predictions.append(np.argmax(o))
print confusion_matrix(y_test,predictions)
print classification_report(y_test,predictions)As output we get a confusion matrix (yup, such a thing exists :))) and a nice report (all from the nice scikit-learn package):
[[50 0 0 0 0 0 0 0 0 0]
[ 0 39 1 0 0 0 0 1 2 6]
[ 0 0 52 0 0 0 0 0 0 0]
[ 0 0 2 34 0 1 0 0 5 0]
[ 0 1 0 0 35 0 1 1 0 0]
[ 0 0 0 0 0 50 1 0 0 1]
[ 0 0 0 0 0 0 37 0 4 0]
[ 0 0 0 0 0 0 0 47 0 1]
[ 0 0 0 0 0 1 1 0 38 1]
[ 0 0 1 0 0 1 0 1 1 33]]
precision recall f1-score support
0 1.00 1.00 1.00 50
1 0.97 0.80 0.88 49
2 0.93 1.00 0.96 52
3 1.00 0.81 0.89 42
4 1.00 0.92 0.96 38
5 0.94 0.96 0.95 52
6 0.93 0.90 0.91 41
7 0.94 0.98 0.96 48
8 0.76 0.93 0.84 41
9 0.79 0.89 0.84 37
avg / total 0.93 0.92 0.92 45093% Accuracy is not bad for a simple 50 line model with no optimizations done. Of course there are many things that could be done to improve the models, such as adding regularization, momentum, and many other things, which I hope I will be doing this summer.


