Indexing IM logs with Elasticsearch


Remember my old project for processing instant messaging logs? Probably, because I wrote about it five years ago. Well, the project is only mostly dead, every once in a while I still occasionally work on it.
I mostly use it as an excuse to learn technologies that are used outside of the Google bubble. One thing that really impressed me with how well it works and how easy it is to set up was Elasticsearch. Elasticsearch is a search engine. You give it your documents and it indexes them and enables you to query them fast. There are other projects that do this for you, but ES can do scaling to multiple machines out of the box, has sane defaults for how to process text and it has many addons. One of the amazing addons, built by the same company, is Kibana, a dashboard and reporting tool, perfectly integrated with Elasticsearch.
Let's see how we can get our data into Elasticsearch and how we can learn something from it. We're going to use the Python bindings and I assume that you have all the official packages installed. I'm going to assume that getting the data is a solved problem and we basically have an iterator that produces dictionaries of the following form:
{'datetime': '2017-03-30T23:12', 'message': 'Hello there', 'contact':
'Friend', 'sender': 'Me'}To add the data into Elasticsearch, we use the following super short snippet:
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
es = Elasticsearch()
# Create the connection to the Elasticsearch cluster
es = Elasticsearch(['http://elastic:changeme@localhost:9200/'])
# Set a certain property for the message field.
es.indices.create('chat', {"mappings" : {
"message" : {
"properties" : {
"message" : {
"type" : "text",
"fielddata": True
}
}
}
}
})
# Generator that creates dictionaries of our messages and tells ES were to index
# them
def lines():
for row in rows:
d = {k: row[k] for k in row.keys()}
d['_op_type'] = 'index'
d['_index']= 'chat'
d['_type']= 'message'
yield d
# Imports into Elasticsearch in bulk (once every 5000 messages)
bulk(es,lines())And that's about it. Normally, Elasticsearch can create indexes automatically when you first import something, but in our case, it has a wrong default for the message field, so we have to manually specify that it should have the fielddatasetting true.
Now let's see what this gives us. We are going to start Kibana, which is the dashboard creating tool for Elasticsearch. There we can explore our dataset and filter by everything:
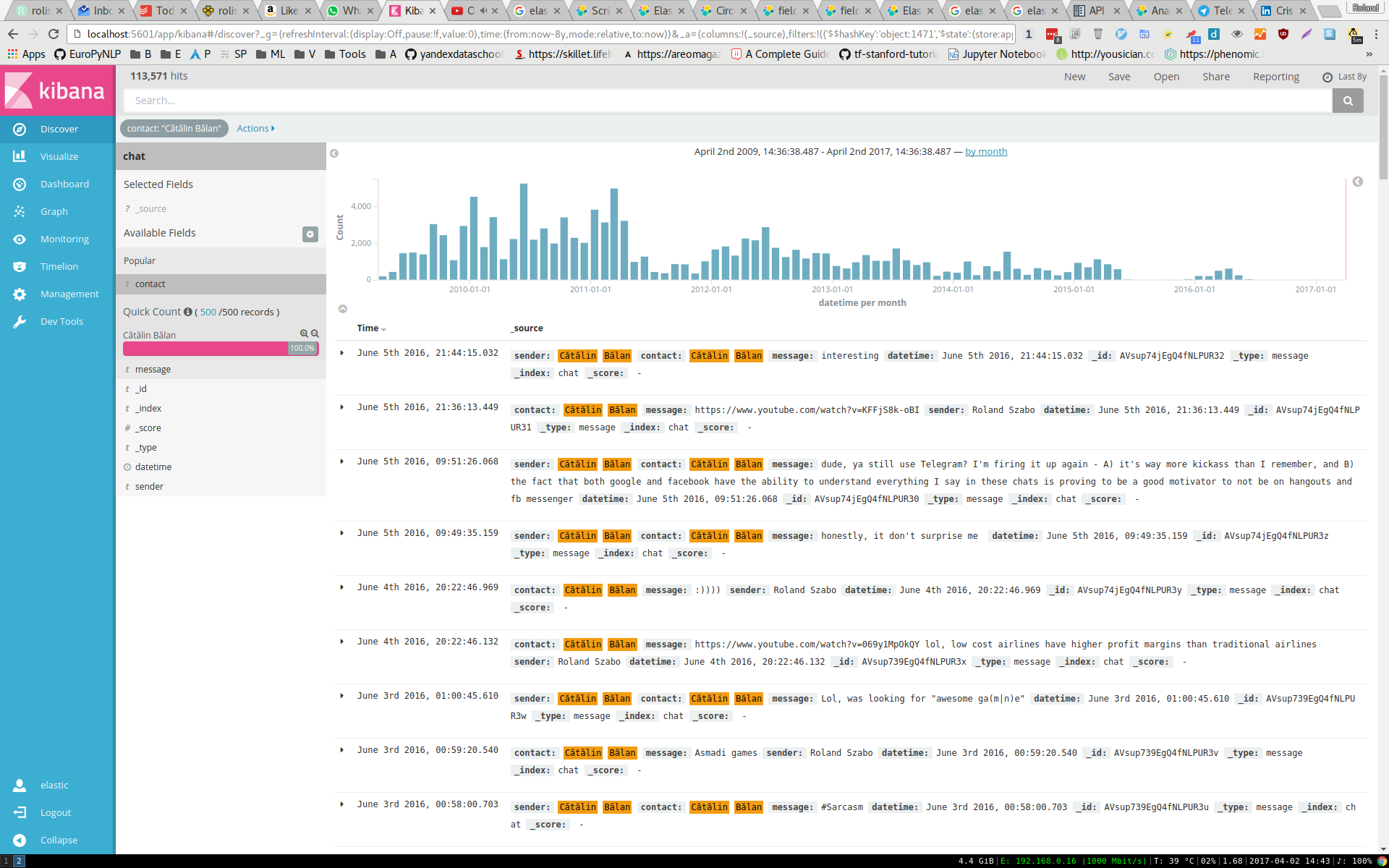
This shows you some of my discussions with Cătălin. At the top you can see the number of messages we've had over the years. It's a partial lie: in the second half of 2015 we talked over Wire and I didn't save my discussions from there and since the second half of 2016 we've been talking on Telegram and I haven't written the import tool for that.
Below that you can see some of the actual messages, with all the metadata. It's quite nice to explore your data and to reminisce over old conversations.
Then we can switch to the Visualize tab and create some pretty graphs:
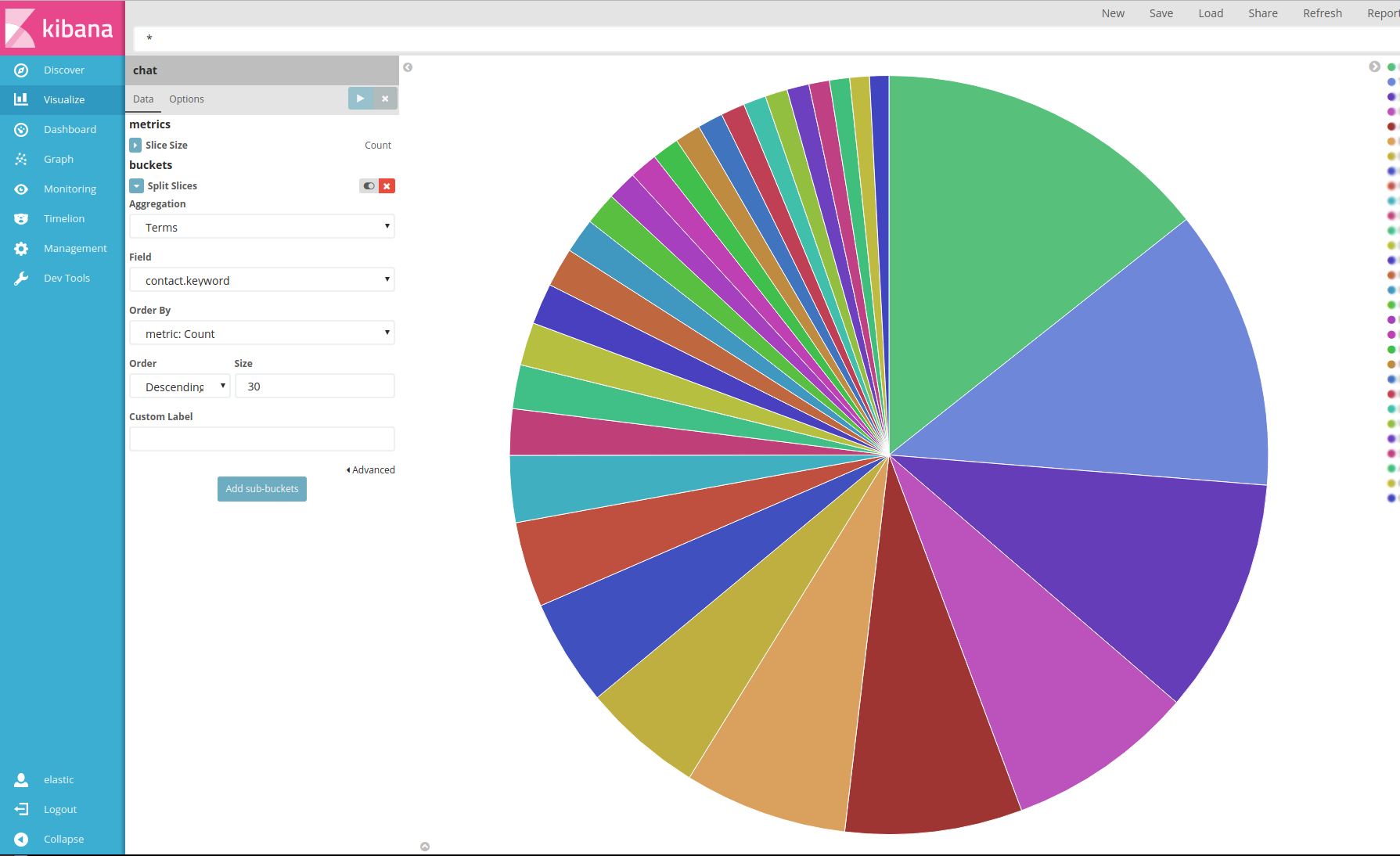
This is a graph of the top 20 people I have talked with. Cătălin leads the pack, because I have been talking to him for about 9 years and then there are various friends. One thing that was surprising to me was how some people with whom I haven't talked in 3-4 years are still there, meaning that I must've talked to them a loooot before that.
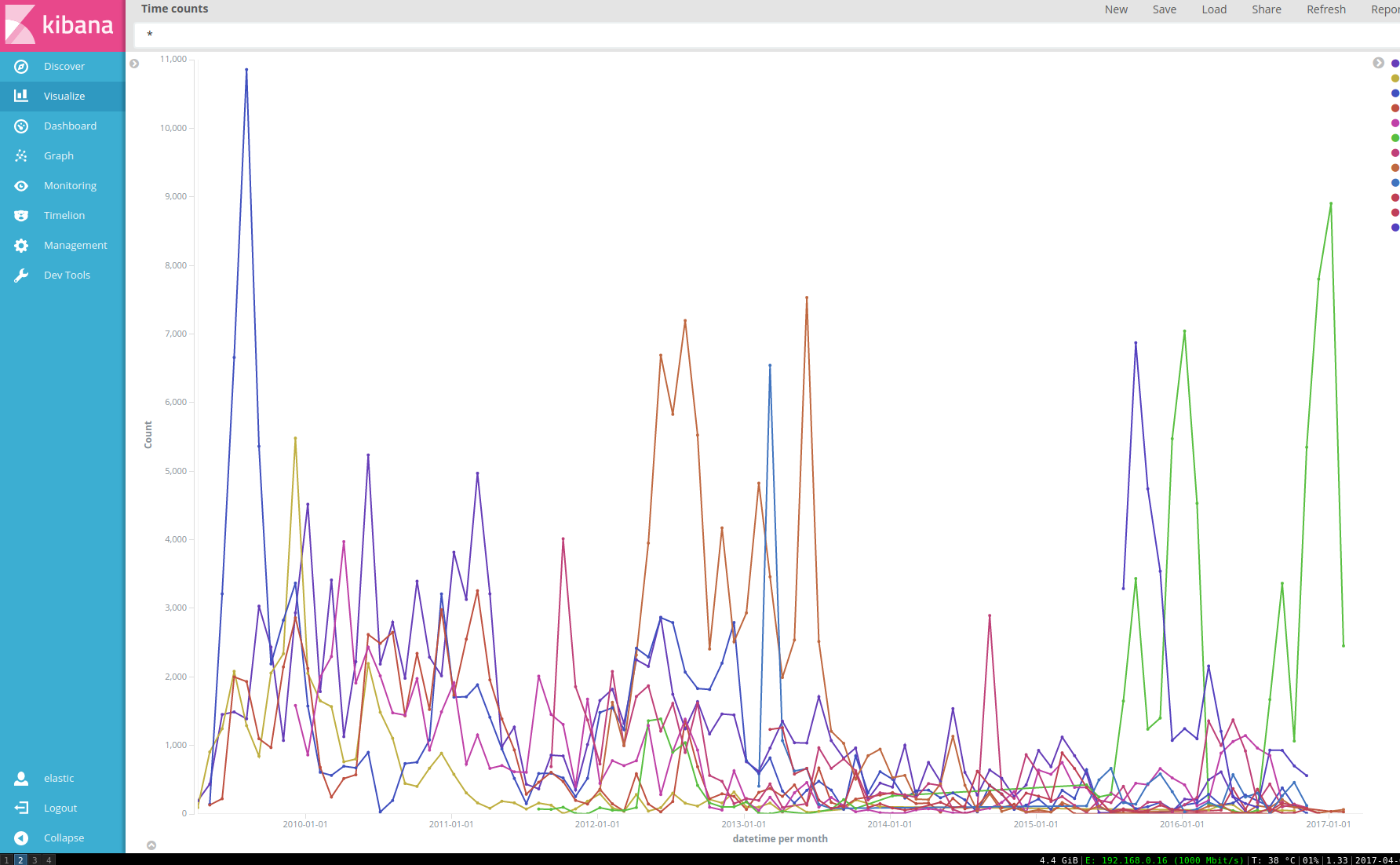
Another easy graph to make is to plot how much I've talked to my top 20 contacts over the years. As you can see, there is a lot of variation. It's hard to tell much just by eyeballing the data, but it seems that most of the time there are burst of activity with a friend and then we talk much less for a while. Maybe I should use it to decide who to talk to again. :D
The last thing I want to show is from an addon to Elasticsearch, called X-Pack. It's a paid addon, but it has a free 30 day trial. It has a module called Graph, where you enter certain keywords and it shows you related terms.
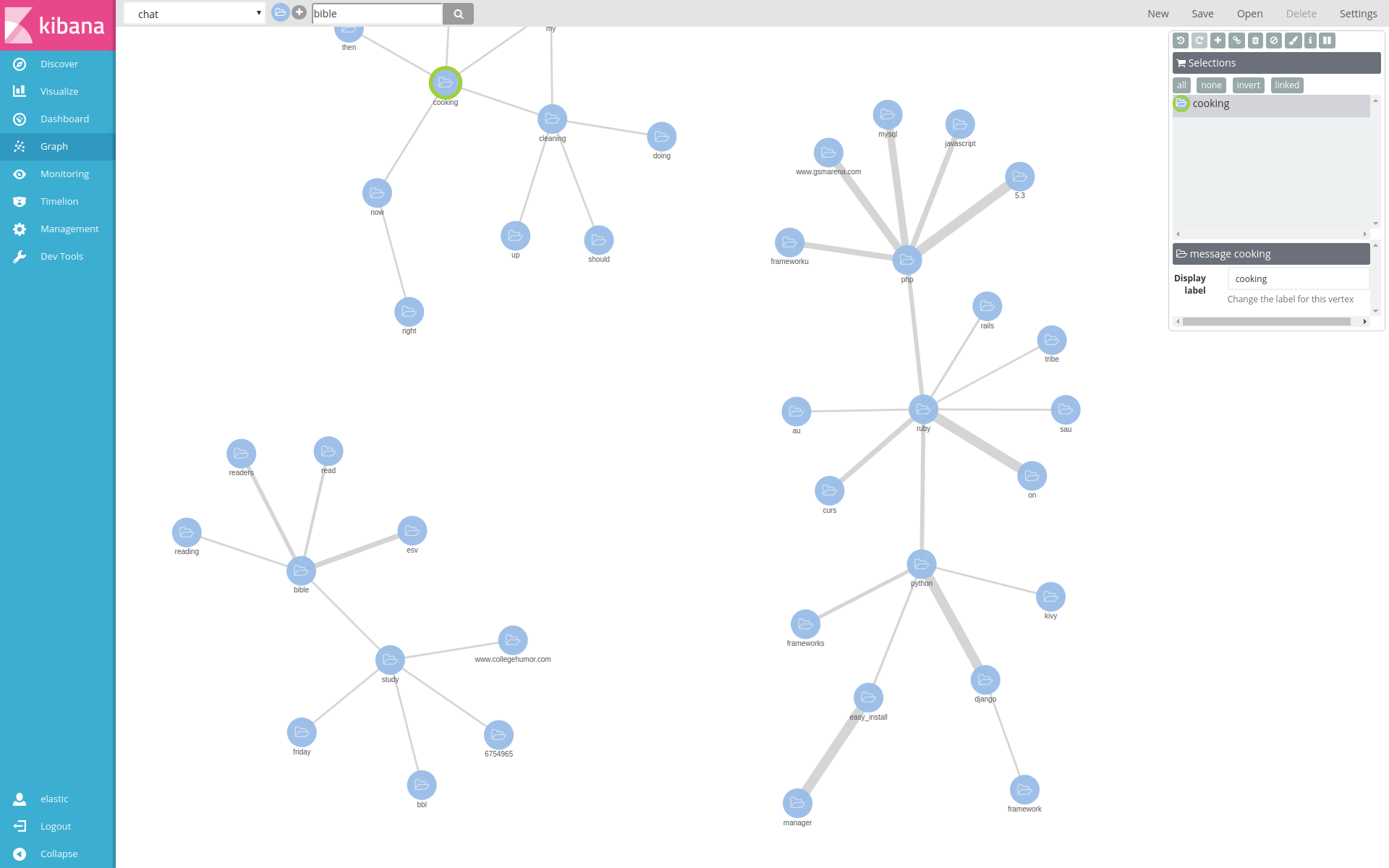
To get this image, I entered Python, Ruby, cooking and Bible. As you can see, it "knows" that Python and Ruby are connected. Even more, it knows that Django is a Python framework, while Rails is a Ruby framework. PHP and Javascript are also programming languages, so they are part of that cluster.
But cooking forms a different cluster, together with cleaning, which I should be doing :D
Bible is another separate cluster, with study and reading. It figured out that I use the ESV Bible translation. The relationship between study and collegehumor is funny: I sent a certain link to many people, which was about "studying" and this confuses it into thinking the two are related. Alas, humor still beats modern AI techniques.
Considering how much effort we invested into this, it gives really good results. Of course, it's helpful that I have a lot of data from which it can learn.
I find Elasticsearch a great tool for quickly searching when I talked to someone about a certain topic and for doing some simple visualizations. It's super simple to use, but still powerful.


